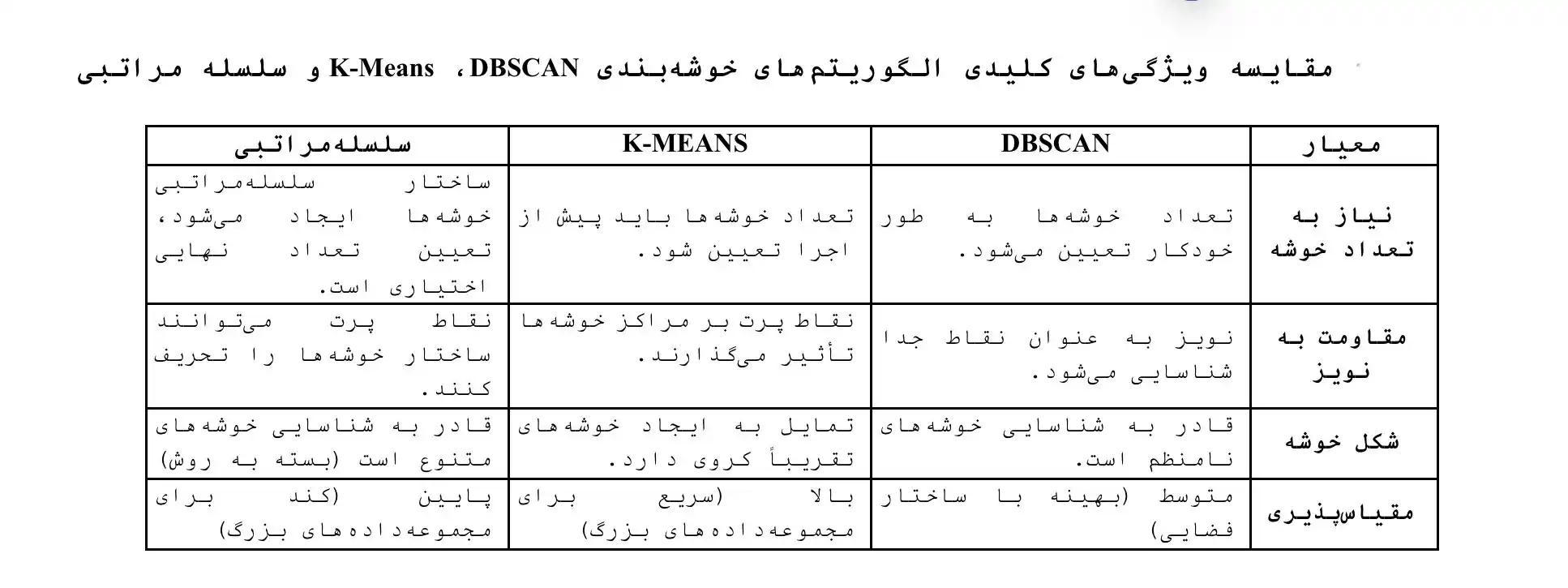
در اینجا به مقایسه سه الگوریتم پرکاربرد خوشه بندی، شامل DBSCAN (یک روش مبتنی بر چگالی)، K-Means (یک روش مبتنی بر مرکز) و خوشه بندی سلسله مراتبی (یک روش مبتنی بر ساختار درختی)، بر اساس ویژگی های کلیدی آنها می پردازیم. این مقایسه به درک بهتر نقاط قوت و ضعف هر الگوریتم در مواجهه با اهداف خوشه بندی کمک می کند.
الگوریتم DBSCAN، با توانایی ذاتی خود در شناسایی خوشه هایی با اشکال مختلف و مدیریت نقاط پرت به عنوان نویز، یک ابزار قدرتمند در تحلیل داده های پیچیده به شمار می رود. با این حال، وابستگی عملکرد آن به انتخاب مناسب پارامترهای ϵ و MinPts و چالش های موجود در مواجهه با داده های با ابعاد بالا و خوشه هایی با تراکم متغیر، محدودیت های قابل توجهی را برای کاربرد گسترده آن ایجاد می کند.در راستای رفع این محدودیت ها، الگوریتم های بهبود یافته ای نظیر OPTICS و HDBSCAN توسعه یافته اند که هر یک با رویکردهای نوآورانه خود، سعی در ارتقاء عملکرد خوشه بندی مبتنی بر چگالی دارند. OPTICS با تولید یک ترتیب از نقاط و فواصل دسترسی پذیری، امکان استخراج خوشه ها در سطوح مختلف تراکم را فراهم می آورد، از سوی دیگر، HDBSCAN با ساخت یک ساختار سلسله مراتبی از خوشه ها و استفاده از مفهوم پایداری، به طور موثرتری قادر به شناسایی خوشه هایی با تراکم های متفاوت است و خروجی نهایی آن برای کاربر نهایی معمولا قابل فهم تر است.مقایسه الگوریتم های مبتنی بر چگالی با روش های کلاسیک خوشه بندی نظیر K-Means و خوشه بندی سلسله مراتبی، نقاط قوت و ضعف هر رویکرد را در سناریوهای مختلف داده ای آشکار می سازد. در حالی که K-Means برای داده های با توزیع یکنواخت و خوشه های کروی کارآمد است و خوشه بندی سلسله مراتبی امکان بررسی ساختار خوشه بندی در سطوح مختلف را می دهد، هر دو روش در مواجهه با خوشه های غیرکروی و نقاط پرت با چالش هایی روبرو هستند که الگوریتم های مبتنی بر چگالی در این زمینه ها عملکرد بهتری از خود نشان می دهند. با این حال، کارایی محاسباتی و حساسیت به پارامترها همچنان از جمله ملاحظات مهم در انتخاب و استفاده از الگوریتم های مبتنی بر چگالی به شمار می روند.