امیررضا جهانتاب
10 یادداشت منتشر شدهPrecision، Recall و F۱-Score: مفاهیم کلیدی در ارزیابی مدل های یادگیری ماشین
مقدمه: در دنیای یادگیری ماشین و پردازش داده ها، معیارهای مختلفی برای ارزیابی عملکرد مدل های طبقه بندی وجود دارد. سه معیار مهم و پرکاربرد که در این زمینه استفاده می شوند عبارت اند از Precision (دقت)، Recall (بازخوانی) و F1-Score. این معیارها به ما کمک می کنند که بفهمیم مدل ما چقدر در تشخیص نمونه های درست موثر عمل کرده است. در این مقاله به طور مفصل و با زبانی ساده به توضیح این مفاهیم می پردازیم.
Precision یا دقت نشان می دهد که از میان تمام نمونه هایی که مدل به عنوان «مثبت» پیش بینی کرده، چند مورد واقعا مثبت بوده اند. به عبارت دیگر، دقت به ما می گوید که چقدر مدل ما در پیش بینی نمونه های مثبت، دقیق عمل کرده است.
فرمول Precision:
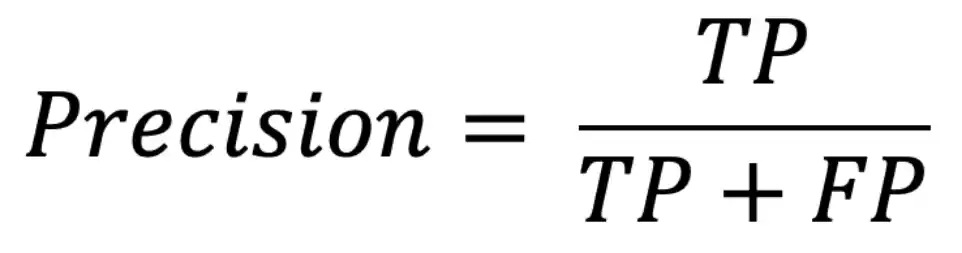
TP (True Positive): تعداد مواردی که واقعا مثبت بوده و مدل آن ها را مثبت پیش بینی کرده است.
FP (False Positive): تعداد مواردی که واقعا منفی بوده اما مدل آن ها را به اشتباه مثبت پیش بینی کرده است.
✅ مثال ساده برای Precision:فرض کنید یک سیستم تشخیص ایمیل های اسپم داریم. اگر سیستم ۱۰ ایمیل را به عنوان اسپم شناسایی کند و از این ۱۰ مورد، فقط ۷ مورد واقعا اسپم باشند، دقت سیستم ما به صورت زیر محاسبه می شود:
Precision = (7)/(7+3)
یعنی ۷۰٪ از ایمیل هایی که به عنوان اسپم شناسایی شده اند، واقعا اسپم هستند.
Recall نشان می دهد که از میان تمام نمونه های مثبت واقعی، مدل چند مورد را به درستی تشخیص داده است. به عبارت دیگر، بازخوانی مشخص می کند که مدل ما چقدر از نمونه های مثبت را از دست داده است.
فرمول Recall:
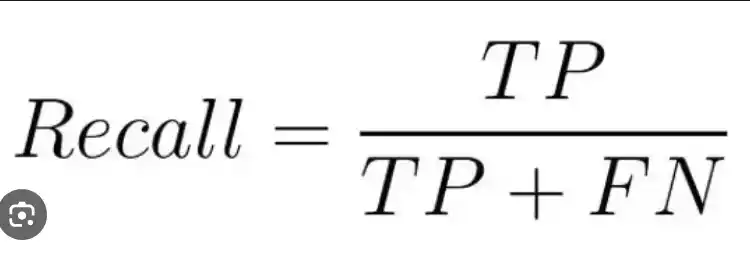
FN (False Negative): تعداد نمونه هایی که واقعا مثبت بوده اند اما مدل آن ها را به اشتباه منفی تشخیص داده است.
✅ مثال ساده برای Recall:فرض کنید در دیتاست ما ۱۵ ایمیل اسپم وجود دارد، اما مدل ما فقط ۷ مورد از آن ها را به عنوان اسپم تشخیص داده است، درحالی که ۸ مورد را از دست داده است. در این صورت، مقدار بازخوانی به شکل زیر محاسبه می شود:
Recall=7/(7+8)=0.47
یعنی مدل ما تنها ۴۷٪ از ایمیل های اسپم واقعی را شناسایی کرده است.
Precision و Recall همیشه در تعادل با یکدیگر نیستند. گاهی افزایش یکی باعث کاهش دیگری می شود:
- اگر بخواهیم Precision را بالا ببریم، باید تعداد FP (موارد مثبت اشتباه) را کاهش دهیم، که معمولا باعث کاهش Recall می شود.
- اگر بخواهیم Recall را بالا ببریم، باید تعداد FN (موارد منفی اشتباه) را کاهش دهیم، که ممکن است باعث کاهش Precision شود.
✅ مثال واقعی:
- در سیستم تشخیص سرطان، Recall مهم تر است، زیرا مهم ترین هدف این است که هیچ مورد سرطانی را از دست ندهیم، حتی اگر برخی نمونه های سالم به اشتباه مثبت شناسایی شوند.
- در سیستم تشخیص تقلب در بانکداری، Precision مهم تر است، زیرا نمی خواهیم افراد بی گناه به اشتباه به عنوان متقلب شناسایی شوند.
برای یافتن تعادلی بین Precision و Recall از F1-Score استفاده می کنیم. این معیار میانگین هارمونیک Precision و Recall است و مقدار متعادلی از هر دو را ارائه می دهد.
فرمول F1-Score:
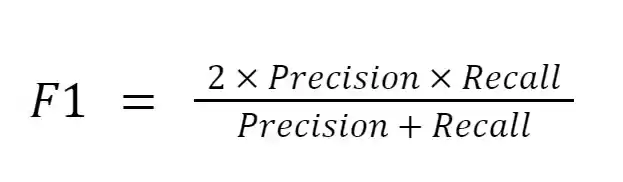
✅ مثال برای F1-Score:فرض کنید که در یک مدل خاص داریم:
- Precision = 0.7
- Recall = 0.47
با استفاده از فرمول F1-Score:
F1-Score = 2 * (0.7 *0.47)/(0.7+0.47) = 0.56
این مقدار نشان می دهد که عملکرد کلی مدل به اندازه ۵۶٪ متعادل و مناسب است.
جمع بندی
- Precision مشخص می کند که مدل چقدر در تشخیص موارد مثبت دقیق عمل کرده است.
- Recall نشان می دهد که مدل چند درصد از نمونه های مثبت واقعی را شناسایی کرده است.
- F1-Score میانگینی متعادل از Precision و Recall ارائه می دهد.
استفاده از این معیارها بستگی به هدف مدل دارد. در بعضی موارد، دقت (Precision) مهم تر است و در بعضی دیگر، بازخوانی (Recall). اما F1-Score گزینه ای مناسب برای زمانی است که بخواهیم تعادلی بین این دو معیار برقرار کنیم.
امیدوارم این مقاله به درک بهتر شما از این مفاهیم کمک کرده باشد!