امیررضا جهانتاب
10 یادداشت منتشر شدهWord Embedding در پردازش زبان طبیعی
مقدمه
در پردازش زبان طبیعی (NLP)، یکی از چالش های اساسی تبدیل کلمات به فرمت عددی است که الگوریتم های یادگیری ماشین قادر به درک آن باشند. یکی از روش های پرکاربرد برای این کار Word Embedding است که کمک می کند کلمات در یک فضای برداری (Vector Space) نمایش داده شوند، به طوری که شباهت معنایی بین آن ها حفظ شود.
Word Embedding به روشی گفته می شود که در آن هر کلمه به یک بردار عددی (Numeric Vector) در یک فضای چندبعدی (Multi-Dimensional Space) تبدیل می شود. هدف از این کار، نمایش معنایی کلمات به گونه ای است که کلمات مشابه به یکدیگر نزدیک تر باشند. به عنوان مثال، در یک مدل Word Embedding، کلمات "پادشاه" و "ملکه" نسبت به "پادشاه" و "میز" فاصله کمتری دارند.
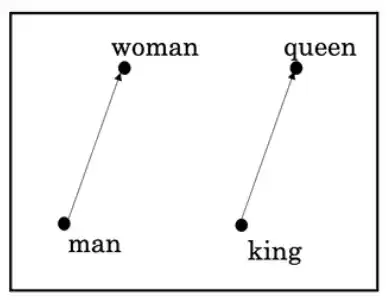
چرا از Word Embedding استفاده می کنیم؟
در گذشته، برای نمایش کلمات در مدل های NLP از روش One-Hot Encoding استفاده می شد، اما این روش مشکلاتی داشت:
- ابعاد بالا (High Dimensionality): اگر یک واژگان شامل 100,000 کلمه باشد، هر کلمه باید در یک بردار 100,000 بعدی نمایش داده شود.
- عدم نمایش شباهت معنایی (Lack of Semantic Similarity): در روش One-Hot Encoding، هیچ رابطه ای بین کلمات مشابه در نظر گرفته نمی شود.
- حافظه بالا (High Memory Usage): ذخیره سازی بردارهای بزرگ نیازمند فضای زیادی در حافظه است.
- CBOW: پیش بینی کلمه مرکزی (Center Word) با استفاده از کلمات همسایه (Context Words).
- Skip-Gram: پیش بینی کلمات همسایه با استفاده از کلمه مرکزی. این مدل ها با استفاده از شبکه های عصبی (Neural Networks) آموزش داده می شوند.
۳. FastText: این مدل که توسط فیسبوک معرفی شده است، برخلاف Word2Vec که تنها کلمات کامل را بررسی می کند، از زیرکلمه ها (Subwords) نیز استفاده می کند. این ویژگی باعث بهبود نمایش معنایی کلمات نادر (Rare Words) و واژه های جدید (Out-of-Vocabulary Words) می شود.
۴. ELMo (Embeddings from Language Models): این روش بر پایه مدل های یادگیری عمیق (Deep Learning) مانند LSTM (Long Short-Term Memory) کار می کند و بردارهای کلمات را بر اساس مفهوم جملات مختلف تغییر می دهد.
۵. BERT (Bidirectional Encoder Representations from Transformers): این مدل که توسط گوگل توسعه داده شده است، از ساختار Transformer استفاده کرده و برخلاف مدل های قبلی، اطلاعات را در هر دو جهت جمله بررسی می کند. این ویژگی باعث می شود که معنای یک کلمه در متن های مختلف متفاوت باشد.
نتیجه گیری
Word Embedding نقش مهمی در بهبود عملکرد مدل های پردازش زبان طبیعی دارد. با استفاده از روش هایی مانند Word2Vec، GloVe، FastText و BERT، می توان نمایش برداری بهتری از کلمات به دست آورد که درک معنایی بهتری برای مدل های یادگیری ماشین فراهم می کند. انتخاب روش مناسب به نوع داده و کاربرد موردنظر بستگی دارد، اما در کل استفاده از Word Embedding یک گام کلیدی برای بهبود عملکرد مدل های NLP است.