نگاهی به مفهوم لایه ها و معماری لایه ای هوش مصنوعی با تاکید بر نگاه مقام معظم رهبری امام خامنه ای (مد ظله العالی) به تسلط بر لایه ها
اگر بخواهیم تعریف ساده ای از هوش مصنوعی داشته باشیم، می توان هوش مصنوعی را در قالب شبیه سازی فرآیندهای هوش انسانی توسط ماشین ها، به ویژه سیستم های کامپیوتری، تعریف کرد. این فرآیندها می تواند شامل «یادگیری» (Learning)، «استدلال» (Reasoning) و «خود اصلاحی» (Self Correction) باشند. منظور از یادگیری، فرآیند تصاحب (یا تغییر) دانش، اطلاعات، قوانین، مقادیر یا ترجیحات جدید (یا موجود) در جهت بهبود تعامل با محیط عملیاتی است. استدلال، به استفاده از قوانین برای رسیدن به نتایج «تقریبی» (Approximate) یا «قطعی» (Definite) اطلاق می شود. «آلن تورینگ» (Alan Turing)، که به او لقب پدر علوم کامپیوتر نظری (Theoretical Computer Science) و هوش مصنوعی داده شود، هوش مصنوعی را به عنوان «علم و مهندسی ساختن ماشین های هوشمند، به ویژه برنامه های کامپیوتری هوشمند» تعریف کرده است.
انواع فناوری های هوش مصنوعی
انواع فناوری های هوش مصنوعی را می توان به دو روش مختلف دسته بندی کرد. در روش اول، فناوری های هوش مصنوعی بر اساس قابلیت ها، نحوه کاربرد و دامنه مسائلی که می تواند در آن اقدام به حل مساله کنند، دسته بندی می شوند. در روش دوم، فناوری های هوش مصنوعی بر اساس ویژگی ها و قابلیت های ذاتی به گروه های مختلف دسته بندی می شوند.
دسته بندی نوع اول
در این دسته بندی، فناوری های هوش مصنوعی به دو گروه «هوش مصنوعی ضعیف» (Weak Artificial Intelligence) و «هوش مصنوعی عمومی» (General Artificial Intelligence) یا «هوش مصنوعی قوی» (Strong Artificial Intelligence) دسته بندی می شوند:
- «هوش مصنوعی ضعیف» (Weak Artificial Intelligence): سیستم هوش مصنوعی است که برای انجام وظایف خاصی ساخته شده و آموزش دیده است. بسیاری از سیستم های کامپیوتری هوشمند کنونی که ادعا می کنند از فناوری های هوش مصنوعی برای انجام وظایف خود استفاده می کنند، در این دسته بندی قرار می گیرند و برای حل مسائل خاص و دامنه بسیار محدود استفاده می شوند. این دسته از فناوری های هوش مصنوعی، در نقطه مقابل هوش مصنوعی قوی یا عمومی قرار دارند. دستیارهای شخصی مجازی نظیر «سیری» (Siri) شرکت «اپل» (Apple) از جمله چنین سیستم هایی هستند.
- «هوش مصنوعی عمومی» (General Artificial Intelligence): سیستم هوش مصنوعی است که که ظرفیت فهمیدن یا یادگیری هر کار فکری را (که توسط انسان قابل انجام است) دارند. به عبارت دیگر، در چنین سیستم هایی، «قابلیت های شناختی» (Cognitive Abilities) انسانی به ماشین ها تعمیم داده شده اند. چنین سیستم هایی، وقتی که با وظایف ناآشنا روبرو می شوند، بدون دخالت انسانی قادر به یافتن جواب مساله خواهند بود. این سیستم ها، هنوز در مرحله تحقیق قرار دارند و تاکنون، نمونه ای از چنین سیستم هایی ساخته نشده است.
دسته بندی نوع دوم
در این دسته بندی، فناوری های هوش مصنوعی بر اساس ویژگی ها و قابلیت های ذاتی به چهار دسته تقسیم بندی می شوند. این دسته بندی ها عبارتند از:
- «ماشین های واکنش گرا» (Reactive Machines): این دسته، ساده ترین شکل فناوری های هوش مصنوعی است. این دسته از فناوری های هوش مصنوعی، حافظه ندارند؛ نمی توانند یادگیری کنند و قادر به استفاده از اطلاعات گذشته برای انجام وظایف آینده نیستند. این سیستم ها، در هر مرحله، تمامی راه های ممکن برای حل مسئله را می سنجند. سپس، بهترین استراتژی ممکن را انتخاب می کنند.
- «ماشین های با حافظه محدود» (Limited Memory): این دسته از فناوری های هوش مصنوعی قادرند از اطلاعات گذشته، برای تصمیم گیری در مورد وظایف آینده استفاده کنند. برخی از قابلیت های تصمیم گیری موجود در «اتومبیل های خودران» (Self-Driving Automobiles)، به این شکل طراحی شده اند. مشاهدات انجام شده و اطلاعات به دست آمده از وضعیت های پیشین، در تصمیم گیری هایی که در آینده اتخاذ می شوند، دخیل هستند (نظیر تعویض خطوط رانندگی توسط اتومبیل). مشاهدات انجام شده، به طور دائم ذخیره نمی شوند.
- «نظریه ذهن» (Theory of Mind): این دسته از هوش مصنوعی، توانایی فهمیدن احساسات، عقاید، افکار و توقعات انسان ها را خواهد داشت و می تواند تعاملات اجتماعی با انسان ها داشته باشد. اگرچه تاکنون تحقیقات زیادی در این زمینه انجام شده است، اما، تاکنون این دسته از فناوری های هوش مصنوعی، به واقعیت مبدل نشده اند.
- «هوش خودآگاهی» (Self-Awareness Intelligence): سیستم هوش مصنوعی است که هوشیاری، هوش فوق العاده، خودآگاهی و احساس داشته باشد؛ به عبارت دیگر، یک انسان کامل باشد. چنین سیستم هایی وجود خارجی ندارند و پیاده سازی آن ها، نقطه عطف و مقصد نهایی حوزه هوش مصنوعی محسوب می شوند.
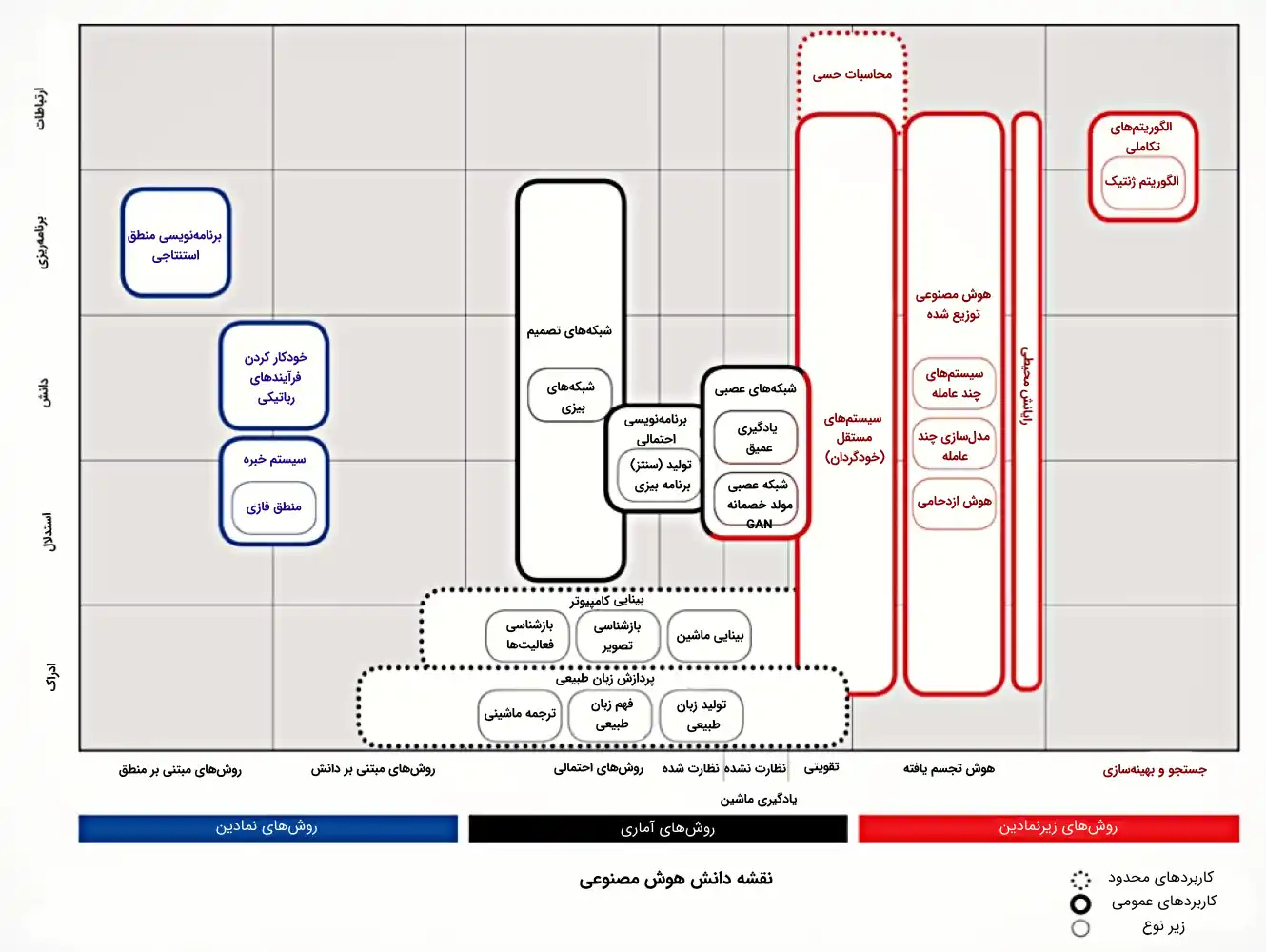
- نقشه دانش پیش رو می تواند به عنوان مدخلی برای دسترسی به دانش موجود در حوزه هوش مصنوعی نیز تلقی شود. چنین رویکردی، به خوانندگان و محققان اجازه می دهد تا منابع مختلف را برای دستیابی به اطلاعات اضافی جستجو کنند و در نهایت دانش جدیدی در این حوزه تولید کنند. به همین خاطر، به این مدل، نقشه دانش فناوری های هوش مصنوعی گفته می شود. شکل زیر، نقشه دانش فناوری های هوش مصنوعی را نشان می دهد.
- گروه بندی کلان فناوری های هوش مصنوعی در محورهای افقی و عمودی نمایش داده شده است. محور افقی، «الگوهای هوش مصنوعی» (Artificial intelligence Paradigms) را نمایش می دهد. الگوهای هوش مصنوعی، رویکردهایی هستند که برای حل مسائل مرتبط با هوش مصنوعی، توسط محققین و فعالان این حوزه مورد استفاده قرار می گیرند. محور عمودی، «دامنه مسائل هوش مصنوعی» (Artificial Intelligence Problem Domain) را نمایش می دهد. دامنه مسائل هوش مصنوعی، انواع مسائلی را نشان می دهد که توسط فناوری های هوش مصنوعی قابل حل هستند. دامنه مسائل هوش مصنوعی، به نوعی، قابلیت های یک الگوریتم هوش مصنوعی را نیز نمایش می دهد.
دامنه مسائل هوش مصنوعی
محور عمودی، دسته بندی مسائلی را نمایش می دهد که توسط فناوری های هوش مصنوعی قابل هستند. دسته بندی ارائه شده از مسائل هوش مصنوعی، استاندارد این حوزه است.
- «استدلال» (Reasoning): استفاده از قوانین، روابط، مجموعه ها و قضایای موجود در علم منطق برای حل مسائل پیچیده در حوزه فناوری های هوش مصنوعی نظیر تشخیص پزشکی و ایجاد زبان طبیعی توسط کامپیوتر
- «دانش» (Knowledge): قابلیت نمایش و فهم محیط پیرامون برای ایجاد چارچوب های لازم برای حل مسئله
- «برنامه ریزی» (Planning): قابلیت تعریف اهداف و انجام مرحله به مرحله فعالیت های لازم برای رسیدن به آن ها
- «ارتباطات» (communication): قابلیت شناختن زبان (منظور، زبان طبیعی انسان ها) و ارتباط برقرار کردن از این طریق
- «ادراک» (Perception): قابلیت تبدیل کردن ورودی های خام حس شده (نظیر تصویر، صدا و سایر موارد) به اطلاعات مفید و قابل استفاده برای حل مسائل.
الگوهای هوش مصنوعی
در این بخش، الگوهای هوش مصنوعی و یا به عبارت دیگر، روش های حل مسائل در فناوری های هوش مصنوعی، مورد بررسی قرار گرفته و تعریف می شوند. در ابتدا، هر کدام از الگوهای هوش مصنوعی تعریف می شوند.
در بخش های بعدی، طبقه بندی الگوریتم های شناخته شده هوش مصنوعی شرح داده شده و هر کدام از الگوریتم ها تعریف می شوند.
- ابزارهای مبتنی بر منطق (Logic-based): این ابزارها، برای نمایش دانش در دامنه مسائل هوش مصنوعی و حل مسائل هوش مصنوعی استفاده می شوند.
- ابزارهای مبتنی بر دانش (Knowledge-based): این ابزارها، مبتنی بر «آنتولوژی» ( Ontology | هستان شناسی) و پایگاه های دانش ساخت یافته عظیم (متشکل از مفاهیم، تعاریف، اطلاعات و قوانین) هستند.
- روش های احتمالی (Probabilistic Methods): روش ها و ابزارهایی هستند که به عوامل درگیر در محیط مساله اجازه می دهند که در سناریوهای حاوی «اطلاعات ناکامل» (incomplete Information)، به حل مساله بپردازند.
- یادگیری ماشین (Machine Learning): ابزارهایی هستند به الگوریتم های کامپیوتری اجازه می دهند تا بتوانند الگوها و مدل های داده ای را یاد بگیرند.
- هوش تجسم یافته (Embodied Intelligence): ابزارهای مهندسی هستند که فرض می کنند شکل گیری یک بدنه (و یا حداقل یک مجموعه جزئی از قابلیت ها نظیر حرکت، ادراک، تعامل و بصری سازی) برای تولید یک هوش مصنوعی کامل و یا یک موجودیت با هوش بالاتر الزامی است.
- جستجو و بهینه سازی (Search and Optimization): با استفاده از چنین ابزارهایی، امکان پیاده سازی روش های هوشمند جستجو در فضای جواب های مساله (با قابلیت تولید بیش از یک جواب برای مساله) فراهم می آید.
تمامی الگوهای شرح داده شده، در یک طبقه بندی دیگر نیز قرار می گیرند:
- رویکردهای نمادین (Symbolic Approaches): این رویکردها در شکل بالا با رنگ آبی نمایش داده شده اند. این دسته از رویکردها بیان می کنند که هوش انسانی، قابلیت ها و عملکردهای آن از طریق روش های نمادین (مانند نظریه منطق فازی) قابل تعریف و دستکاری هستند.
- رویکردهای زیر-نمادین (Sub-Symbolic Approaches): این رویکردها در شکل بالا با رنگ قرمز نمایش داده شده اند. در این رویکردها، هیچ نوع خاصی از نمایش دانش دامنه، پیش از پیاده سازی الگوریتم های هوش مصنوعی در دسترس نیست.
- رویکردهای آماری (Statistical Approaches): در این رویکرد، از روش ها و ابزارهای آماری برای حل مسائل حوزه هوش مصنوعی استفاده می شود.
سیستم های خبره
«سیستم های خبره» (Expert Systems)، نمونه ای از ابزارهای مبتنی بر منطق و دانش هستند. این فناوری، مجموعه ای از برنامه های کامپیوتری را شامل می شود که با استفاده از قوانین کدبندی شده در پیکره آن ها، توانایی همانندسازی فرایند تصمیم گیری خبره انسانی را دارند. این دسته از سیستم ها، برای حل مسائل بسیار پیچیده در حوزه هوش مصنوعی طراحی شده اند. در این دسته از روش ها، حقایق و قوانین لازم برای عملیاتی کردن سیستم، توسط قوانین (If-Then) در یک پایگاه دانش مدل سازی می شوند. سیستم خبره روی این پایگاه دانش، استنتاج منطقی انجام می دهد و از این طریق، به حل مسائل هوش مصنوعی می پردازد. مهم ترین نمونه سیستم های خبره، «سیستم های فازی» (Fuzzy Systems) هستند.
الگوریتم های تکاملی (Evolutionary Algorithms)
زیر شاخه ای از محاسبات تکاملی هستند. الگوریتم هایی برای حل مسائل بهینه سازی هستند و شامل تکنیک هایی می شوند که از مکانیزم های الهام گرفته شده از تکامل زیستی (نظیر «جهش» (Mutation)، «ترکیب» (Recombination)، «تولید مثل» (Reproduction)، «انتخاب طبیعی» (Natural Selection) و «بقای بهترین ها» (Survival of Fittest)) برای تولید جواب های کاندید حل مساله استفاده می کنند.
به این مکانیزم ها، عملگرهای تکاملی نیز گفته می شود. جواب های کاندید، نقش نمونه ها در جمعیت را ایفا می کنند و «تابع هزینه» (Cost Function)، برازندگی محیطی که جواب کاندید در آن قرار دارد را مشخص می کند. پس از تعدادی نسل، جمعیت جواب های کاندید از طریق عملگرهای تکاملی، به سمت جواب های بهینه تکامل پیدا می کنند. الگوریتم هایی نظیر الگوریتم ژنتیک، الگوریتم کلونی مورچگان، الگوریتم شبیه سازی تبرید، الگوریتم بهینه سازی فاخته و سایر موارد از جمله الگوریتم های تکاملی هستند.
در این جا لازم است تفاوت میان دو اصطلاح «اکتشافی» (Heuristics) و فرا اکتشافی شرح داده شود. این دو اصطلاح، برای نام گذاری الگوریتم تکاملی جستجو و بهینه سازی استفاده می شوند. با این حال، تفاوت های اساسی با یکدیگر دارند که در ادامه به آن ها پرداخته می شود.
- الگوریتم های اکتشافی (Heuristics): این دسته از الگوریتم ها، روش های وابسته به مساله (Problem-Dependent) هستند. مشخصات این الگوریتم ها، بسته به مساله ای که قرار است بهینه سازی کنند، متفاوت خواهد شد. از آنجایی که این الگوریتم ها، بسیار حریصانه (Greedy) هستند، بسیار در دام «بهینه محلی» (Local Optimum) قرار می گیرند و نمی توانند به خوبی به جواب «بهینه سراسری» (Global Optimum) همگرا شوند.
- الگوریتم های فرا اکتشافی (Meta-Heuristics): در نقطه مقابل الگوریتم های اکتشافی، الگوریتم های فرا اکتشافی قرار دارند. این دسته از روش ها، مستقل از مساله (Problem-Independent) هستند و مشخصات آن ها برای حل مسائل بهینه سازی مختلف، یکسان خواهد بود. از آنجایی که حریصانه نیستند، تقریب نزدیک از جواب بهینه سراسری را نیز به عنوان جواب بهینه می پذیرند. در نتیجه، می تواند فضای جواب های مساله را با دقت بیشتری بسنجند و در بسیاری از موارد، جواب بهینه بسیار خوب و حتی بهینه سراسری را تولید کنند.