امیررضا جهانتاب
10 یادداشت منتشر شدهSkip-gram در Word۲Vec
چکیده
مدل Skip-gram یکی از روش های اصلی در Word2Vec است که برای یادگیری بردارهای کلمه (Word Embeddings) در پردازش زبان طبیعی (NLP) استفاده می شود. این مدل با یادگیری روابط معنایی بین کلمات از طریق پیش بینی کلمات مجاور یک کلمه ی هدف، توانایی تولید بردارهایی با ویژگی های معنایی و نحوی را دارد. در این مقاله، ابتدا به بررسی مفهوم Word2Vec پرداخته، سپس جزئیات مدل Skip-gram، تابع هزینه، نحوه ی بهینه سازی، و روش Negative Sampling برای بهبود کارایی آموزش را شرح خواهیم داد. در پایان، یک راهنمای عملی برای پیاده سازی مدل ارائه خواهد شد که خواننده بتواند این روش را در پروژه های خود استفاده کند.
۱. مقدمه
امروزه پردازش زبان طبیعی (NLP) به یکی از حوزه های مهم در یادگیری ماشین (ML) تبدیل شده است. مدل های مبتنی بر NLP در کاربردهایی مانند ترجمه ماشینی، تحلیل احساسات، چت بات ها، و بازیابی اطلاعات مورد استفاده قرار می گیرند. یکی از مسائل کلیدی در NLP، نحوه ی نمایش داده های متنی برای استفاده در مدل های یادگیری ماشین است.
روش های سنتی مانند One-hot Encoding و TF-IDF با مشکلاتی همچون ابعاد بالا، عدم درک معنایی، و محاسبات پیچیده مواجه بودند. برای حل این مشکلات، مدل Word2Vec معرفی شد که کلمات را در قالب بردارهای متراکم با ویژگی های معنایی و نحوی نمایش می دهد. Word2Vec دو معماری اصلی دارد:
Continuous Bag of Words (CBOW): پیش بینی کلمه ی هدف از روی کلمات اطراف

Skip-gram: پیش بینی کلمات اطراف از روی کلمه ی هدف
در این مقاله، به طور خاص روی مدل Skip-gram تمرکز خواهیم کرد و آن را از جنبه های مختلف تحلیل خواهیم کرد تا خواننده بتواند آن را در پروژه های عملی پیاده سازی کند.
۲. مدل Skip-gram در Word2Vec ۲.۱. ایده ی اصلی Skip-gramمدل Skip-gram به جای پیش بینی کلمه ی هدف از روی کلمات مجاور (مانند CBOW)، برعکس عمل کرده و سعی می کند از یک کلمه ی ورودی، کلمات اطراف آن را پیش بینی کند. فرض کنید جمله ی زیر را داریم:
"The quick brown fox jumps over the lazy dog"اگر کلمه ی "fox" را به عنوان کلمه ی هدف انتخاب کنیم و پنجره ی (window size) = 2 در نظر بگیریم، مدل باید از روی "fox"، کلمات مجاور {"quick", "brown", "jumps", "over"} را پیش بینی کند.
۲.۲. معماری شبکه ی عصبی Skip-gram
مدل Skip-gram از یک شبکه ی عصبی کم عمق تشکیل شده است که شامل سه لایه ی اصلی است:
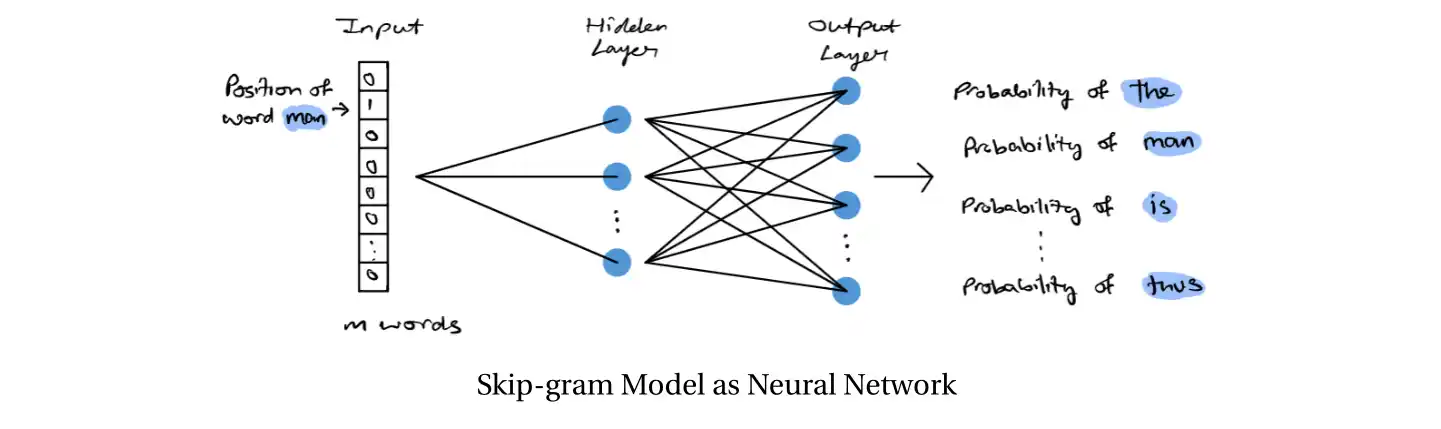
- لایه ی ورودی: یک کلمه ی هدف به عنوان ورودی دریافت می شود و به یک بردار one-hot تبدیل می شود.
- لایه ی مخفی: یک ماتریس وزن های تعبیه ای (Embedding Weights) در این لایه قرار دارد که نقش نگاشت کلمات به بردارهای متراکم را ایفا می کند.
- لایه ی خروجی: احتمال وقوع هر کلمه ی زمینه ای در خروجی محاسبه می شود. این کار از طریق تابع Softmax انجام می شود.
۲.۳. تابع هزینه ی Skip-gram
مدل Skip-gram با استفاده از تابع احتمال شرطی سعی می کند احتمال وقوع یک کلمه ی زمینه w_o را در اطراف کلمه ی مرکز w_c بیشینه کند:
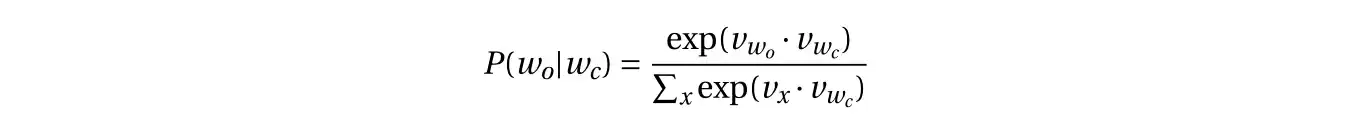
که در آن:
- w_c و w_o بردارهای تعبیه ای برای کلمه ی مرکز و کلمه ی زمینه هستند.
- V مجموعه ی تمام کلمات در واژگان است.
تابع هزینه ی مدل برابر است با منفی لگاریتم احتمال شرطی روی کل مجموعه ی داده:
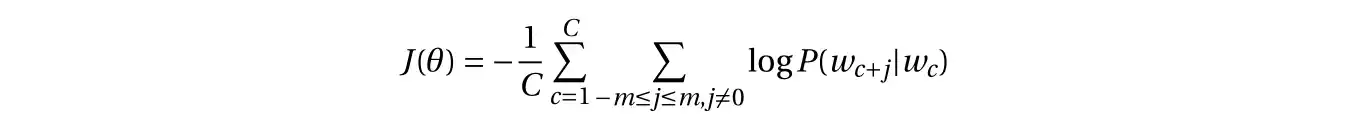

۳. بهینه سازی مدل Skip-gram با Negative Sampling
یکی از مشکلات مدل Skip-gram این است که محاسبه ی تابع Softmax نیازمند جمع روی تمام واژگان است که برای مجموعه های داده ی بزرگ بسیار هزینه بر خواهد بود. برای حل این مشکل، روش Negative Sampling پیشنهاد شده است.
۳.۱. مفهوم Negative Sampling
به جای محاسبه ی احتمال برای تمام کلمات موجود در واژگان، در هر مرحله ی آموزش تنها چند کلمه ی منفی (کلماتی که در آن زمینه ظاهر نشده اند) انتخاب می شوند. به عبارت دیگر:
- برای هر جفت (کلمه ی مرکز، کلمه ی زمینه) یک برچسب مثبت (1) اختصاص داده می شود.
- چند کلمه ی تصادفی از میان کل واژگان انتخاب شده و به عنوان نمونه های منفی با برچسب منفی (0) استفاده می شوند.
- مدل یاد می گیرد که احتمال نمونه های مثبت را بالا ببرد و احتمال نمونه های منفی را کاهش دهد.
۴. نتیجه گیری
مدل Skip-gram یکی از قدرتمندترین روش ها برای یادگیری بردارهای کلمه است که با یادگیری روابط معنایی و نحوی بین کلمات می تواند در بسیاری از کاربردهای NLP مفید باشد. این مدل به دلیل توانایی خود در یادگیری روابط معنایی دقیق تر و کار با مجموعه های داده ی بزرگ، نسبت به CBOW ترجیح داده می شود.